
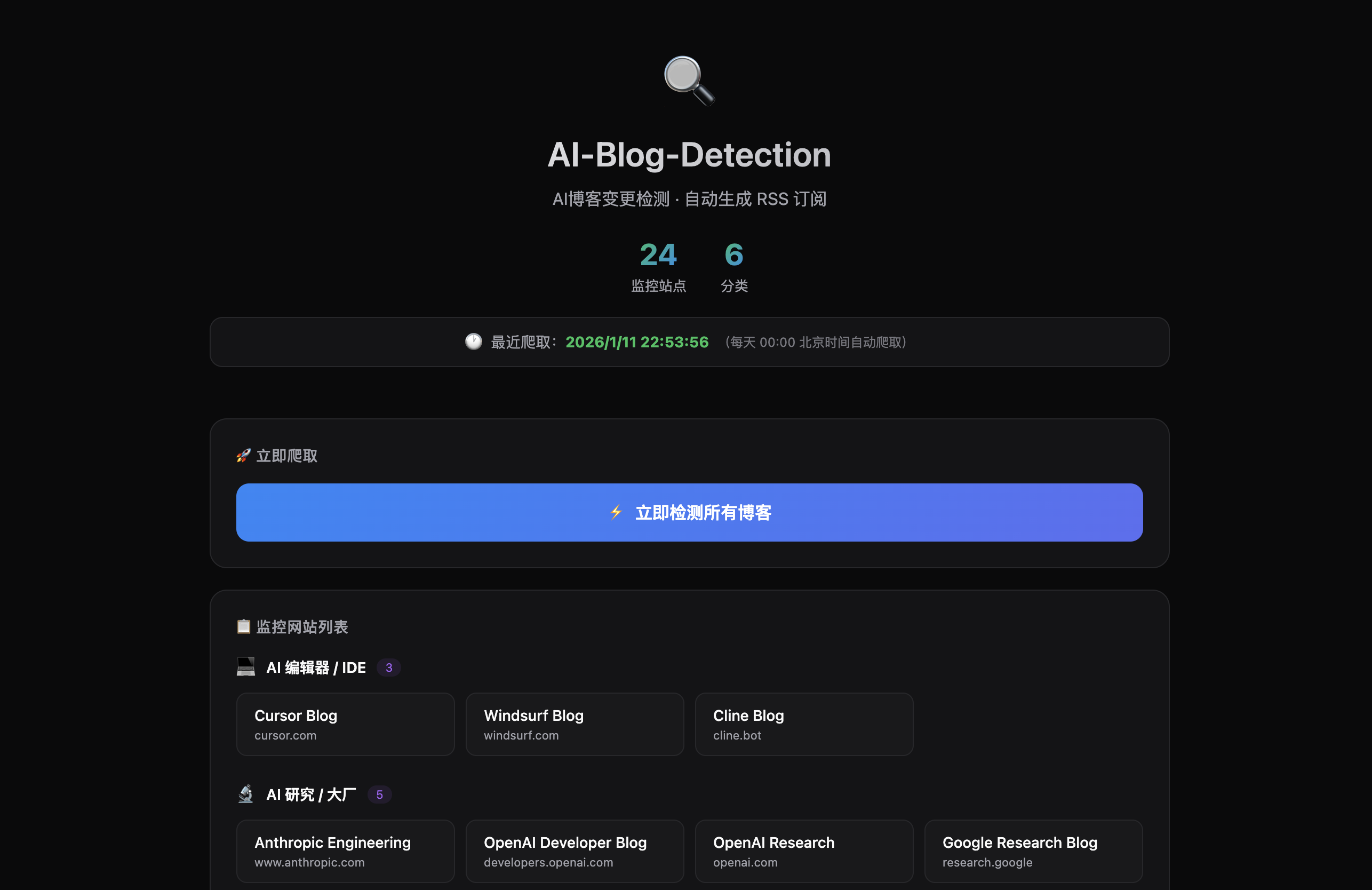
1. 原由
上周在阅读文章的时候,发现其实当前很多成熟的AI产品,他们都会将自己的一些经验分享成博客,这些知识有些是他们在项目开发中趟过的坑,有些是一些新奇的思路,有些是一些新功能,对于我们这些追随者来说,都是一些非常好的经验,值得借鉴,学习,思考。
但是这些博客他们都是在官网开的tab页,并没有提供rss,大量的平台,让我每天逐个去点开看是否有新文章,也比较耗时耗力。
我已经有了阅读inoreader的习惯,这是一个非常好的rss订阅平台,免费的账户都能订阅很多的rss,像上面这些没有提供rss的网页,其实inoreader也提供了解决方法,可以检测页面元素生成rss。但是要收费,哈哈。
之前遇到了这个问题,我只能放弃了,所以对于那些没有rss的网站,只能看一眼,少一眼,不过现在有了AI工具,就不是问题了,自己写一个,哈哈。
其实我最开始是想找别人写好的,不过找来找去也没有啥合适的,有个很强的changedetection.io, 我部署了他的免费docker版本,体验了一下,功能太多,太复杂,且试了一下,老是失败。遂放弃。
2. 开始
最开始想着用Python写,部署在本地然后生成rss,通过我的公网ip暴露出去,不过这都是消耗我的本地资源,且我不太想暴露自己的服务器,所以就用ts写,部署到vercel,直接cursor一把梭哈哈。
这里面有几个坑记录一下:
- 最开始我还是后端思路,各种网站的配置保存到json,然后ts读取写入,发现ts对于这种json文件处理不是很好,直接就用ts的一个文件,将所有的网站信息放里面了:
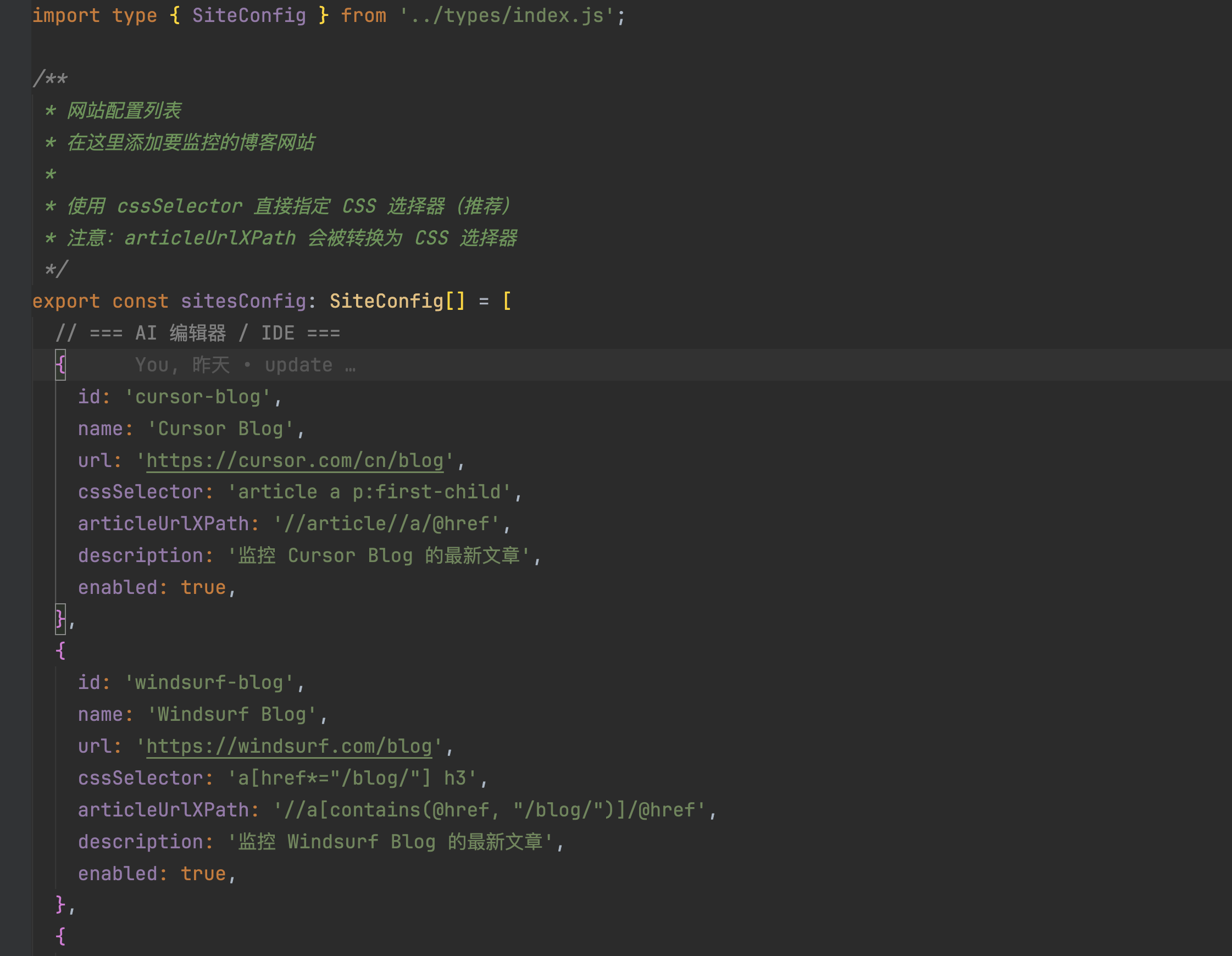
- 最开始cursor推荐用的vercel的KV存储,我部署了一个vercel的edge storage,使用了一把就发现容量超了,😅
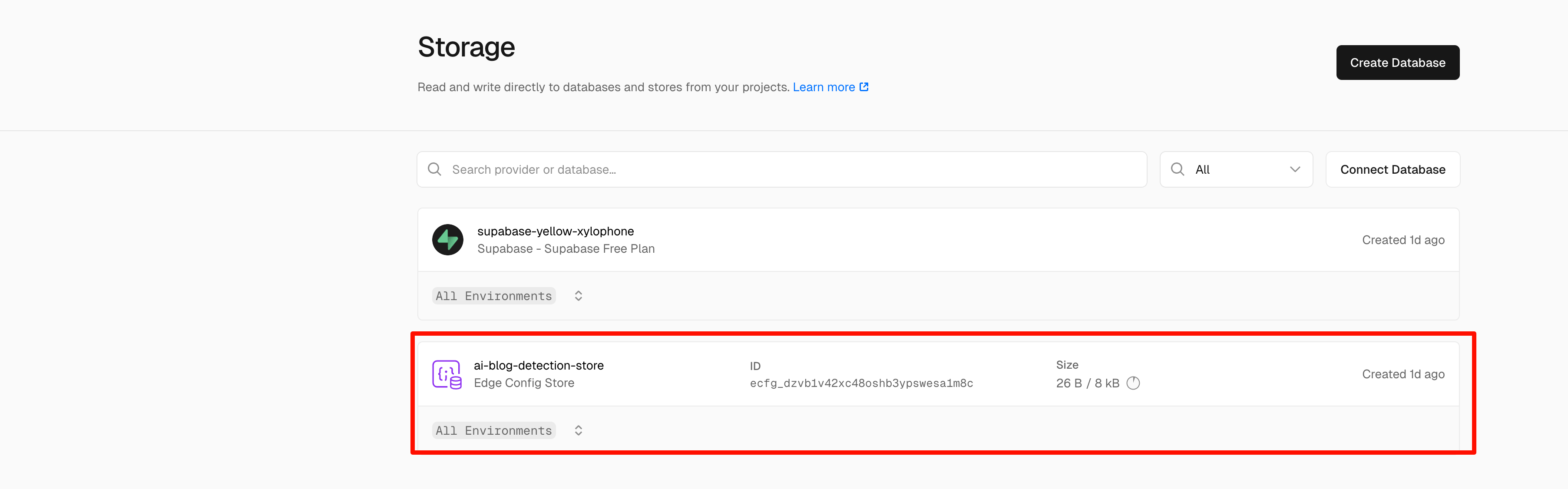
后续更换了supabase的免费pg数据库,supabase真乃善人,提供的免费存储有500M,足够用了,而且vercel的storage中直接提供了supabase创建实例,直接将创建好的密钥信息配置到了环境变量,我的工程直接读就好了。真是顺畅。
- 这里再讲一下如何配置新的博客网站,我最开始是找到每一个博客的文章的html元素,拷贝下来让cursor提取xpath,但我发现cursor提取出来的在ts抓取全局页面的时候,就玩不转了。我这里就笨了,其实你直接把博客的url给他,cursor自己会打开chrome进行提取,速度快,效果好,还能自己完成测试。真是厉害。
3. 项目

shushu1234/AI-Blog-Detection
自动抓取官方AI网站并生成RSS
再来说说这个项目,AI生成的README已经讲的很清楚了,哈哈,按部就班来就好。
评论