
1 优秀项目汇总
1.1 OmniDocBench

opendatalab/OmniDocBench
[CVPR 2025] A Comprehensive Benchmark for Document Parsing and Evaluation
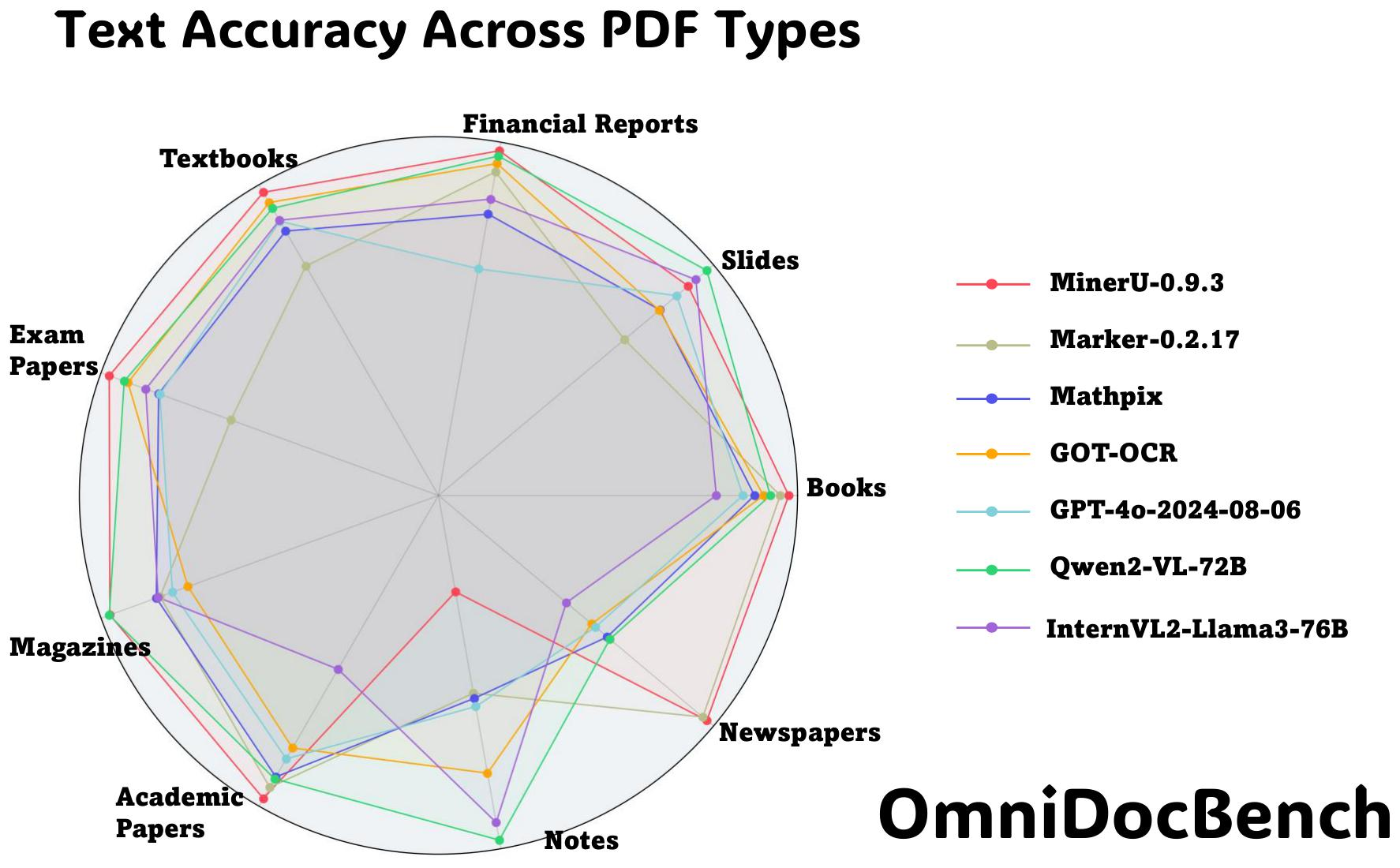
里面对比了各种模型在各种 PDF 文档下面的解析情况,可以发现对于手写的如果不是依赖大模型的检测的话,是比较难解析出好的结果,但是对于杂志的解析,MinerU 却可以得很高的分,综合感觉 Qwen 和 MinerU 可以尝试一下。
1.2 awesome-prompts

browser-use/awesome-prompts
Table of awesome Browser Use prompts
1.3 MegaParse

QuivrHQ/MegaParse
File Parser optimised for LLM Ingestion with no loss 🧠 Parse PDFs, Docx, PPTx in a format that is ideal for LLMs.
1.4 awesome-LLM-resources

WangRongsheng/awesome-LLM-resources
🧑🚀 全世界最好的LLM资料总结(多模态生成、Agent、辅助编程、AI审稿、数据处理、模型训练、模型推理、o1 模型、MCP、小语言模型、视觉语言模型) | Summary of the world's best LLM resources.
各类 LLM 资源汇总
1.5 CasaOS

IceWhaleTech/CasaOS
CasaOS - A simple, easy-to-use, elegant open-source Personal Cloud system.
2 优秀文章
2.1 为什么「上下文检索」是提升 RAG 系统问答准确度的关键?
文章主要讲了在 RAG 中遇到的两个大的问题,chunk 的拆分与查询,当我们 chunk 拆分不合理的时候,容易将连贯的段落拆开,里面提到了将拆开的 chunk 和文章全部上下文交给长上下文模型,来补充上下文,但这样会导致 token 的大量消耗与时间过长问题。
庖丁科技提供了一种新方法:上下文检索方法:该方法通过长上下文重排模型同时对大量文本块进行重排,让文本块在重排阶段获取上下文信息;并通过目录结构模型识别文档的章节目录树,在切分的文本块前加入对应的章节目录,确保文本块的全局信息
2.2 选择一个好的模型

3 工具
3.1 lin-snow/Ech0: Ech0 - 面向个人的新一代开源、自托管、专注思想流动的轻量级联邦发布平台 image.png

lin-snow/Ech0
Ech0 – An open-source, self-hosted lightweight publishing platform for personal idea sharing.
评论