
1. 文章
1.1 我的 2025 年 AI 行业观察:Agent 架构演进、企业 AI 转型现状与 AI 产品趋势 - 莫尔索随笔
-
上下文工程是一门设计系统的学科:这包括上下文卸载(信息外部化)、上下文缩减(历史记录压缩)、上下文检索(动态信息注入)以及上下文隔离(环境解耦)。在 Agent 开发中,系统架构、工具定义及数据检索逻辑本质上都是提示词的组成部分。
-
完善的工具定义(Tool Definition)必须包含清晰的名称与描述、详尽的参数说明(明确每个参数的类型、取值范围及必填项)、应用示例(在描述中直接给出调用示例,例如:「若需查询 X,应按此格式调用工具……」)。
-
此外,工具设计应具备「防御性编程」思维:若模型输入的参数格式略有偏差(如多余空格),工具应尝试自动修正或返回明确的错误提示,而非直接崩溃。工具返回的结果应采用结构化、易于解析的文本,避免返回模型难以理解的二进制数据。
-
Agent 是机会,为 Agent 造工具也是机会
- 计算机使用(Computer Use)与浏览器操作能力(Browser Use)的出现标志着又一次演进。Anthropic 与 OpenAI 相继推出相关功能,使 Agent 能在受控沙箱中模拟人类操作(视觉识别、鼠标点击、键盘输入),并带动了底层云端浏览器基础设施(如 Browserbase、Anchor Browser)的生态繁荣。
- Skill 范式与流程标准化,Claude Code 试图通过 「Skill」 特性打破数据壁垒。其核心逻辑是将企业中可 SOP 化的流程(如品牌风格指引、报告输出、合同拟定等)封装为可复用的指令集。
-
Manus:极致的上下文工程与架构创新
- 精细化的上下文策略:Manus 通过去除冗余并保留核心要素来优化上下文质量。例如,在执行编码任务时,系统仅记录文件路径而非全文内容。
- 借鉴并发哲学的通信机制:多智能体系统常因上下文污染而失效。Manus 借鉴了 Go 语言的并发原则,主张「通过通信共享上下文,而非通过共享内存通信」。对于离散任务,各子 Agent 拥有独立的上下文,仅传递特定指令;仅在处理复杂推理任务时,才谨慎共享完整的上下文历史,以降低缓存压力。
- 分层动作空间:为避免工具过多导致的决策混淆,Manus 建立了三级管理体系:一级核心工具约 20 个高频、稳定的工具,易于缓存;二级沙箱工具,通过通用工具实现特定功能扩展;三级代码单元,利用代码处理复杂的逻辑链条。
-
什么是优秀的 AI 产品
- 以近期备受瞩目的 Nano Banana 模型为例,虽然其具备生成 PPT 的潜力,但在 NotebookLM 中生成的结果往往不可编辑,这大大限制了其实用性。相比之下,Lovart 凭借其强大的分层编辑与文字局部修改能力,反而成功出圈。
- 而 Lovart 的优势在于可以直接导出格式精美、包含源文件的 PPT 演示文档,真正实现了生成即交付。
-
补丁型工具:
- AI 搜索: 这类产品并不构成一个独立的「赛道」,而是模型厂商必然会补齐的原生能力。
- 通用 Agent: 难以形成长期的竞争护城河,随着底层模型能力的不断进化,终将被通用模型直接覆盖。
- 记忆管理补丁: 针对模型记忆能力的外部优化工具同样面临挑战。大家都能看到的痛点,模型厂商自然也能洞察,目前的缺失仅是因为当下的研发重心尚未转移至此。
-
移动互联网时代的核心逻辑是「连接」,在利用网络效应的同时,也造成了一个个中心化的数据孤岛。相比之下,AI 产品的核心价值在于「打通」,通过深度整合长链条流程和数据孤岛,直接产出高价值的最终结果。
-
优秀的 AI 人才应具备系统思维,能冷静判断技术热点,并明确技术能力边界,避免盲目跟风。他们的核心价值在于将技术路径转化为可复现的交付产出与关键指标的提升。
-
取代你的不是 AI,而是会用 AI 的人
-
对个体而言,AI 的学习进化速度意味着传统的职业护城河正在瓦解。
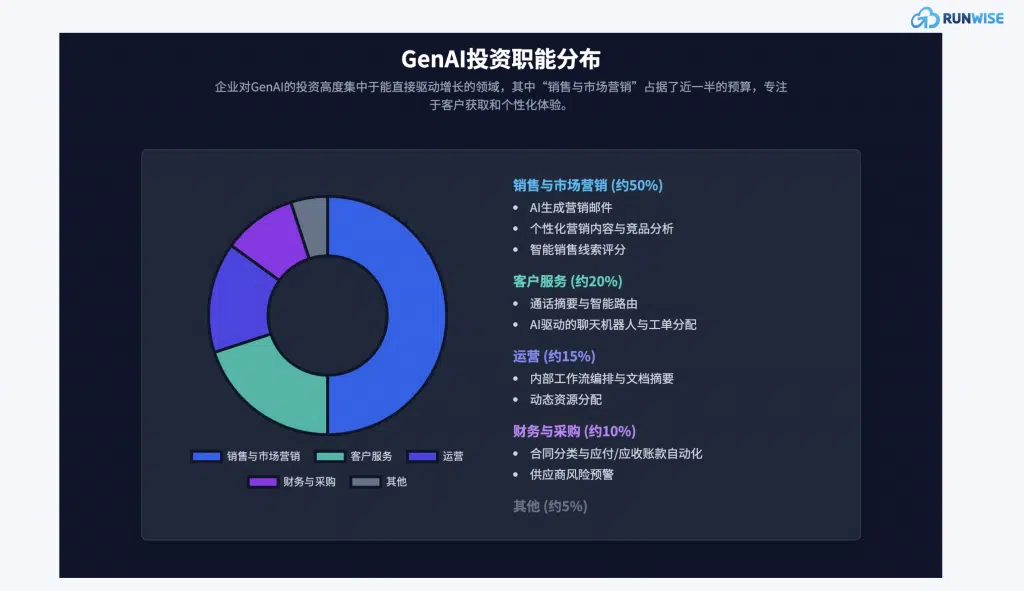
1.2 2025年末全球 AI 行业流量报告:狂热退潮,分化开始 | 宝玉的分享
1.3 动态上下文发现 · Cursor
- 预先提供更少的细节,反而能让 Agent 更容易自主地按需提取相关上下文。我们将这一模式称为 动态上下文发现(dynamic context discovery),与始终被包含的 静态上下文(static context) 相对。
- 动态上下文发现的 token 使用效率要高得多,因为只会将必要的数据引入上下文窗口。但这里和Manus提出的上下文缓存有影响,可能需要动态平衡一下。
- 将较长的工具响应转换为文件。在 Cursor 中,我们则是把输出写入文件,并赋予 Agent 读取该文件的能力。Agent 会调用 tail 来检查末尾内容,如有需要再继续向后读取更多内容。
- 在摘要过程中引用对话历史。Cursor将历史对话将其保存为文件,在后续要使用的时候,可以通过文件引用找回来。
- 支持 Agent Skills 开放标准。SKILL包括了名称和描述,可以放到系统提示词里面,随后Agent可以通过动态上下文进行发现,然后使用grep等其他Cursor的工具进行自动引入SKILL
- 高效地仅加载所需的 MCP 工具。Cursor采用的不是搜索的方式进行获取工具,而是按照服务器创建文件夹,使每一个服务器的工具放在一起,保持逻辑分组,当模型列出某个文件夹的时候,可以看到所有的工具,并将其理解成一个单元,然后可以通过rg(grep的升级版)和jq参数来过滤工具描述信息。
- 将所有集成终端会话视为文件。

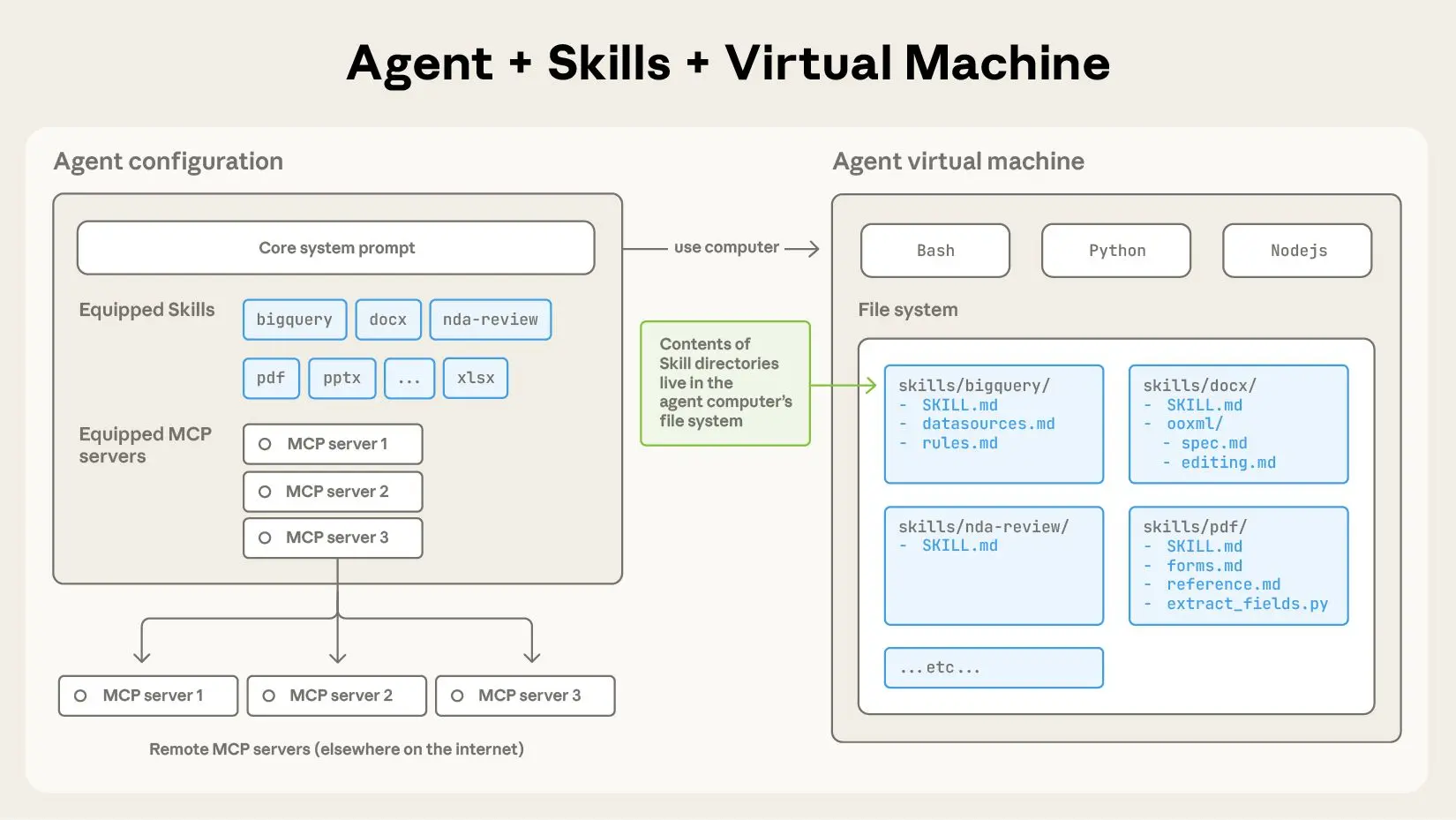
1.4 Agent Skills 终极指南:入门、精通、预测
-
Skill和MCP区别:
- MCP 是一种开放标准的协议,关注的是 AI 如何以统一方式调用外部的工具、数据和服务,本身不定义任务逻辑或执行流程。
- Skill 则教 Agent 如何完整处理特定工作,它将执行方法、工具调用方式以及相关知识材料,封装为一个完整的「能力扩展包」,使 Agent 具备稳定、可复用的做事方法。
-
Skills 是模块化的能力,扩展了 Agent 的功能。每个Skill 都打包了 LLM 指令、元数据、可选资源(脚本、模板等),Agent 会在需要时自动使用他们。
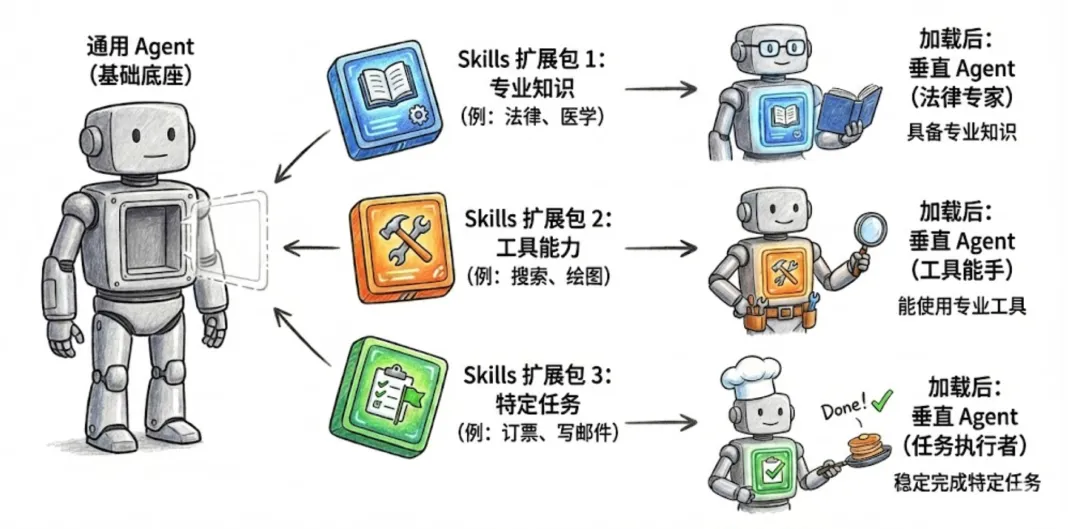




2. 视频
2.1 Manus决定出售前最后的访谈:啊,这奇幻的2025年漂流啊…_哔哩哔哩_bilibili
2.2 Manus全球爆火,我们独家对话Manus创始人肖弘!_哔哩哔哩_bilibili
3. 项目
3.1 TEN-framework/ten-framework: Open-source framework for conversational voice AI agents

TEN-framework/ten-framework
Open-source framework for conversational voice AI agents
3.2 Chapman-John/Multi-Agent-System: Multi-Agent Generative AI System with LangGraph, LangChain, FastAPI and Celery

Chapman-John/Multi-Agent-System
Multi-Agent Generative AI System with LangGraph, LangChain, FastAPI and Celery
┌──────────────┐
│ FastAPI API │ async / Request / Depends
└──────┬───────┘
│
┌──────▼───────┐
│ Service 层 │ async / sync 但「无上下文」
└──────┬───────┘
│
┌──────▼───────┐
│ Infra 层 │ DB / LLM / HTTP
└──────────────┘Celery 只能碰 Service 层。因为celery不能接触到fastapi的上下文,所以在开发时,我们应该让celery只能调用service中的,然后在写service中的方法时需要避免直接使用fastapi中的上下文变量信息。然后在启动任务的时候,我们应该将celery需要的上下文显式的传递进去。
4. 资源
4.1 概述 - 代理技能 — Overview - Agent Skills
这个网站里面讲述了怎么配置agent的skills,里面包包括一个最重要的SKILL.md,还有其他的文件夹,里面可以添加脚本,资源文件等
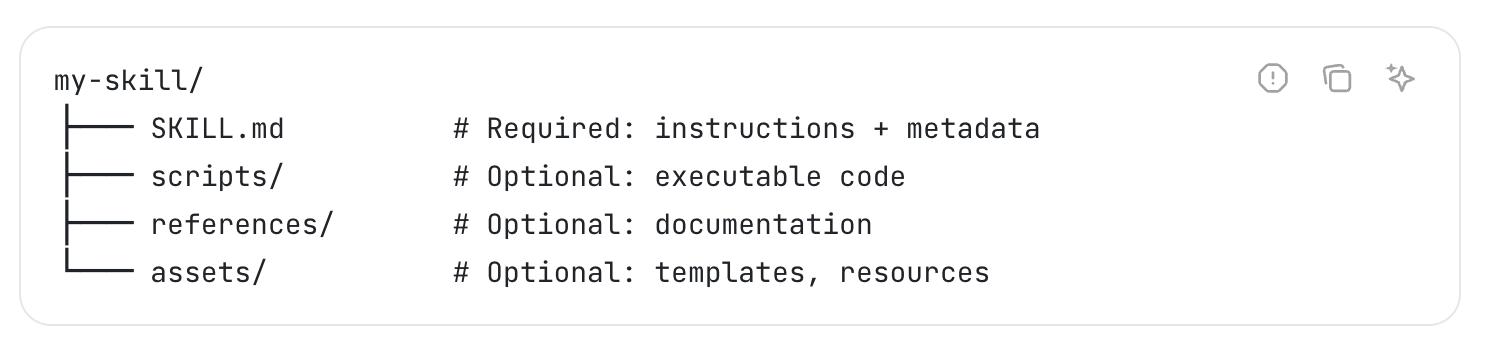
这里一个有个Obsidian的官方Skill库,可以参考:

kepano/obsidian-skills
Agent skills for Obsidian
4.2 2026年掌握人工智能代理的实用指南
一个Agent的学习路线,从最开始的数据开始,然后机器学习,可以做个参考吧
4.3 25页PPT记录一场中国AI“全明星赛” - 屠龙之术 | 小宇宙 - 听播客,上小宇宙
1 月 10 日在北京举行的 AGI-next 论坛活动。
评论