
1. 文章
1.1 为 LLM Agent 编写工具的实战指南:来自 Anthropic 的内部经验(精华版)
-
比如我们内部的"日程安排工具",不是简单包装"创建事件"的 API,而是整合了"查空闲时间"“订会议室"“附上次会议笔记"三个功能 —— LLM 代理用一次调用就能完成任务,比拆成三个工具高效得多。这也是我们常说的:“对代理友好的工具,对人类也往往很直观”。
-
写高效工具的 5 个原则
- 工具要"少而精”,别贪多
- 命名要"明确”,别让代理猜。当工具功能重叠或目的模糊时,代理可能会混淆该使用哪些工具。命名空间化(将相关工具归入共同前缀下)有助于区分大量工具;MCP 客户端有时会默认这样做。
- 返回的内容要"有意义",别给垃圾。在设计工具实现时,应谨慎地只向代理返回高信噪比的信息。这意味着工具应优先考虑信息的上下文相关性,而非过度追求灵活性。代理更容易成功地处理自然语言的名称、术语或标识符
- 优化 token 消耗:别让工具占满上下文。另外,我们还会优化工具响应的格式——比如用 JSON 格式比 XML 格式更省 token,因为 JSON 更简洁,更符合 LLM 的训练数据格式。
- 对工具描述做提示工程:像给新人讲工具一样。工具描述是代理了解工具的"窗口",所以要写得"明确、具体、无歧义"。
1.2 怎么做 Long-running Agents,Cursor、Anthropic 给了两种截然不同的思路
-
Cursor 构建了一个完全扁平化的系统,在这个系统里,所有 Agent 地位平等,通过访问一个共享文件来进行自我协调。
- 从前两次的失败中汲取教训后,Cursor 决定彻底摒弃扁平化的结构,创建一个职责分明的流水线式协作体系,其中包含三个核心角色:
- 规划者(Planner):这个角色的定位类似于团队中的架构师或技术负责人。核心职责不是写代码,是持续地探索和分析整个代码库,理解项目需求。可以为特定的代码模块派生出「子规划者」,让规划过程本身也能实现并行化;
- 工作者(Worker):这个角色是团队中的主力工程师,是纯粹的执行者。从任务池中领取一个任务,然后心无旁骛地完成它。不需要与其他「工作者」进行任何形式的沟通或协调,也完全不必关心项目全局。它们只是专注于执行分配给自己的任务,直到完成,然后提交代码。
-
Claude Code通过引入一个类似人类团队的分工协作机制,将复杂任务拆解成小的可跟踪验证的任务,清晰的交接机制,并且严格验证任务结果。
-
第一步,需要在初始环境中搭建好提示词要求的全部功能基础,让 Agent 能按步骤、按功能推进。
-
第二步,每次会话中的 Agent 必须每次推进一小步,同时将环境保持在「干净状态」。即能随时安全合并到主分支:没有明显 bug、代码整洁、有清晰文档,开发者随时可以继续加新功能。
- 按照这种思路,Anthropic 给 Claude Agent SDK 设计了一个双 Agent 方案:
- 初始化 Agent(Initializer Agent)第一次会话用一个专门提示词,让模型设置初始环境:生成 init.sh 脚本、claude-progress.txt 工作日志文件,以及一个初始 Git 提交。
- 编码 Agent(Coding Agent)在后续会话中接手工作,每次只推进一小步,并为下一轮工作留下清晰信息。
1.3 AI Agent 记忆系统:从短期到长期的技术架构与实践
-
对“记忆”的定义有两个层面:
- 会话级记忆:用户和智能体 Agent 在一个会话中的多轮交互(user-query & response)
- 跨会话记忆:从用户和智能体 Agent 的多个会话中抽取的通用信息,可以跨会话辅助 Agent 推理
-
长期记忆的信息从短期记忆中抽取提炼而来,根据短期记忆中的信息实时地更新迭代,而其信息又会参与到短期记忆中辅助模型进行个性化推理。
-
短期记忆存储会话中产生的各类消息,包括用户输入、模型回复、工具调用及其结果等。
- 核心特点:存储会话中的所有交互消息(用户输入、模型回复、工具调用等)直接参与模型推理,作为 LLM 的输入上下文实时更新,每次交互都会新增消息受模型 maxToken 限制,需要上下文工程策略进行优化
-
长期记忆与短期记忆形成双向交互:一方面,长期记忆从短期记忆中提取“事实”、“偏好”、“经验”等有效信息进行存储(Record);另一方面,长期记忆中的信息会被检索并注入到短期记忆中,辅助模型进行个性化推理(Retrieve)。
- 与短期记忆的交互:Record(写入):从短期记忆的会话消息中提取有效信息,通过LLM进行语义理解和抽取,存储到长期记忆中Retrieve(检索):根据当前用户查询,从长期记忆中检索相关信息,注入到短期记忆中作为上下文,辅助模型推理
-
狭义的上下文工程特指对短期记忆(会话历史)中各种压缩、摘要、卸载等处理机制,主要解决上下文窗口限制和 token 成本问题;
-
广义的上下文工程则包括更广泛的上下文优化策略,如非运行态的模型选择、Prompt 优化工程、知识库构建、工具集构建等,这些都是在模型推理前对上下文进行优化的手段,且这些因素都对模型推理结果有重要影响。
-
短期记忆的上下文处理,主要有以下几种策略:
- 上下文缩减(Context Reduction)上下文缩减通过减少上下文中的信息量来降低 token 消耗,主要有两种方法:1. 保留预览内容:对于大块内容,只保留前 N 个字符或关键片段作为预览,原始完整内容被移除2. 总结摘要:使用 LLM 对整段内容进行总结摘要,保留关键信息,丢弃细节
- 上下文卸载(Context Offloading)上下文卸载主要解决被缩减的内容是否可恢复的问题。当内容被缩减后,原始完整内容被卸载到外部存储(如文件系统、数据库等),消息中只保留最小必要的引用(如文件路径、UUID 等)。当需要完整内容时,可以通过引用重新加载。优势:上下文更干净,占用更小,信息不丢,随取随用。适用于网页搜索结果、超长工具输出、临时计划等占 token 较多的内容。
- 上下文隔离(Context Isolation)通过多智能体架构,将上下文拆分到不同的子智能体中(类似单体拆分称多个微服务)。主智能体编写任务指令,发送给子智能体,子智能体的整个上下文仅由该指令组成。子智能体完成任务后返回结果,主智能体不关心子智能体如何执行,只需要结果。适用场景:任务有清晰简短的指令,只有最终输出才重要,如代码库中搜索特定片段。优势:上下文小、开销低、简单直接。
1.4 从 ReAct 到 Ralph Loop:AI Agent 的持续迭代范式
-
核心思想:同一个提示反复输入,让 AI 在文件系统和 Git 历史中看到自己之前的工作成果。这不是简单的“输出反馈为输入”,而是通过外部状态(代码、测试结果、提交记录)形成自我参照的迭代循环。其技术实现依赖于 Stop Hook 拦截机制。
-
Ralph Loop 让大语言模型持续迭代、自动运行直到任务完成,而不在典型“一次性提示 → 结束”循环中退出。这种范式已经被集成到主流 AI 编程工具和框架中,被一些技术博主和开发者称作“AI 持续工作模式”。
-
智能体被定义为“在循环中运行工具以实现目标的 LLM 系统”。这种定义强调了三个关键属性:
- LLM 编排的推理能力:智能体能够根据观察结果进行推理和决策工具集成的迭代能力:
- 智能体可以调用外部工具并基于工具输出调整行为
- 最小化人工监督的自主性:智能体能够在有限指导下自主完成任务
-
常规 Agent Loop 通常更通用:用于决策型 agent,可以根据多种状态和输入动态调整下一步操作。ReAct 模式适合需要动态适应的场景,Plan-and-Execute 模式适合结构化任务分解。
-
Ralph Loop 更像是自动驱动的 refine-until-done 模式:重点是让模型在固定任务上不断修正输出直到满足完成条件。它通过外部强制控制避免了 LLM 自我评估的局限性。
-
常规智能体的一个核心痛点是“上下文腐烂(Context Rot)”——随着对话轮次的增加,LLM 对早期指令的注意力和精确度会线性下降。Ralph 循环通过“刷新上下文”解决了这一问题:
- 每一轮循环可以看作是一个全新的会话,智能体不再从臃肿的历史记录中读取状态
- 智能体直接通过文件读取工具扫描当前的项目结构和日志文件
- 这种模式将“状态管理”从 LLM 的内存(Token 序列)转移到了硬盘(文件系统)
-
在典型的 Ralph 实现中,智能体会维护以下关键文件:
- progress.txt:一个追加形式的日志文件,记录了每一轮迭代的尝试、遇到的坑以及已经确认的模式。后续迭代的智能体会首先读取该文件以快速同步进度。
- prd.json:结构化的任务清单。智能体每完成一个子项,就会在该 JSON 文件中标记 passes: true。这确保了即使循环中断,新的智能体实例也能明确接下来的优先级。
- Git 提交记录:Ralph 循环被要求在每一步成功后进行提交。这不仅提供了版本回滚能力,更重要的是,它为下一轮迭代提供了明确的“变更差分”(Diff),让智能体能够客观地评估现状。
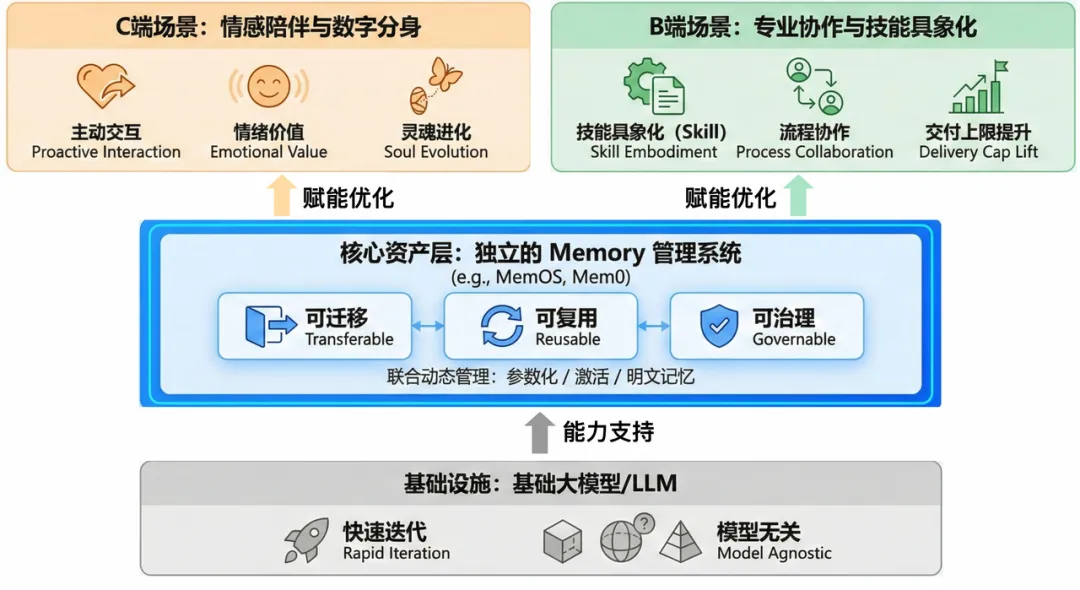
1.5 Agent 真正的护城河,正在从工具转向记忆资产
- 从成本和模型能力上来看,上下文和 RAG 背后有三类硬约束。
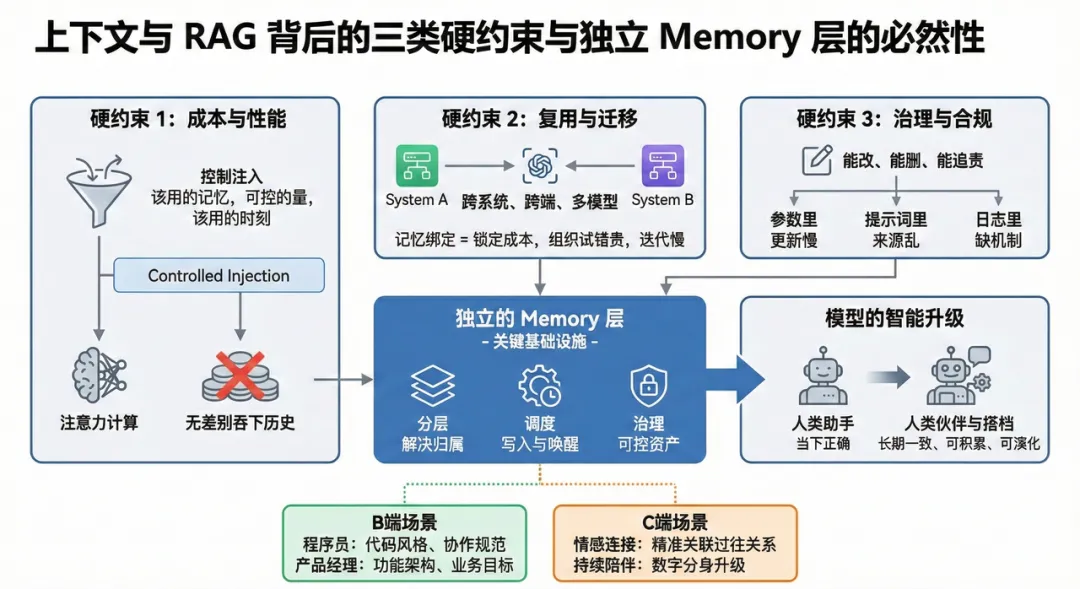
- 让所有模型、所有 agent 都具备记忆能力,让记忆成为各个场景中的通用基础设施。
- 既能服务上层多种 Agent/应⽤,也能适配下层模型的快速迭代,⽽不是被锁死在某个⼊⼝体验⾥。
1.6 7个神级技巧,彻底去除网站的 AI 味儿! - 鱼皮AI导航
推荐的AGENTS.md
# 项目设计规则(AGENTS.md)
## 角色设定
你是一位资深独立设计师,专注于 "反主流" 的网页美学。
你鄙视千篇一律的 SaaS 模板,追求每个像素都有温度。
## ❌ 绝对禁止项
### 配色禁止
- 紫色/靛蓝色/蓝紫渐变(#6366F1、#8B5CF6)
- 纯平背景色(必须有噪点纹理或渐变)
- Tailwind 默认色板
### 布局禁止
- Hero + 三卡片布局
- 完美居中对齐
- 等宽多栏(必须不对称)
### 文案禁止
- 高深的专业名词和无意义的空话
- Lorem Ipsum 占位文本
- 被动语态和长句
### 组件禁止
- Shadcn/Material UI 默认组件(必须深度定制)
- Emoji 作为功能图标
- 线性动画(ease-in-out)
## ✅ 必须遵守项
### 文案风格
- 口语化,像朋友聊天
- 具体化,有数字和场景
- 可以幽默、自嘲、甚至挑衅
- 每句话不超过 15 个字
### 图片系统
- 图标:使用 Iconify 图标库(https://iconify.design)
- 占位图:使用 Picsum Photos(https://picsum.photos)
- 真实图片:使用 Pexels 搜索(https://www.pexels.com)
- 插画:使用 unDraw(https://undraw.co)2. 项目
2.1 op7418/NanoBanana-PPT-Skills: NanoBanana PPT Skills 基于 AI 自动生成高质量 PPT 图片和视频的强大工具,支持智能转场和交互式播放

op7418/NanoBanana-PPT-Skills
NanoBanana PPT Skills 基于 AI 自动生成高质量 PPT 图片和视频的强大工具,支持智能转场和交互式播放
独一份!带动效的 PPT 生成 Agent!使用教学&创作思路 通过 Nano Banana Pro 模型生成图片,并可选导出带转场的视频演示与网页演示界面。
2.3 agentscope-ai/OpenJudge:OpenJudge:一个用于整体评估和质量奖励的统一框架 — agentscope-ai/OpenJudge: OpenJudge: A Unified Framework for Holistic Evaluation and Quality Rewards

agentscope-ai/OpenJudge
OpenJudge: A Unified Framework for Holistic Evaluation and Quality Rewards
2.4 pipipi-pikachu/pptxtojson: Office PowerPoint(.pptx) file to JSON | 将 PPTX 文件转为可读的 JSON 数据

pipipi-pikachu/pptxtojson
Office PowerPoint(.pptx) file to JSON | 将 PPTX 文件转为可读的 JSON 数据
2.5 pipipi-pikachu/PPTist: PowerPoint-ist(/‘pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, allowing for the editing and presentation of PPT online. Support AIPPT.
pipipi-pikachu/PPTist
PowerPoint-ist(/'pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, allowing for the editing and presentation of PPT online. Support AIPPT.
2.6 gitbrent/PptxGenJS: Build PowerPoint presentations with JavaScript. Works with Node, React, web browsers, and more.

gitbrent/PptxGenJS
Build PowerPoint presentations with JavaScript. Works with Node, React, web browsers, and more.

评论